NER using RNNs and Transformer Models
Sara Ericson, Andrew Campbell, Jorge Sanchez
Dataset
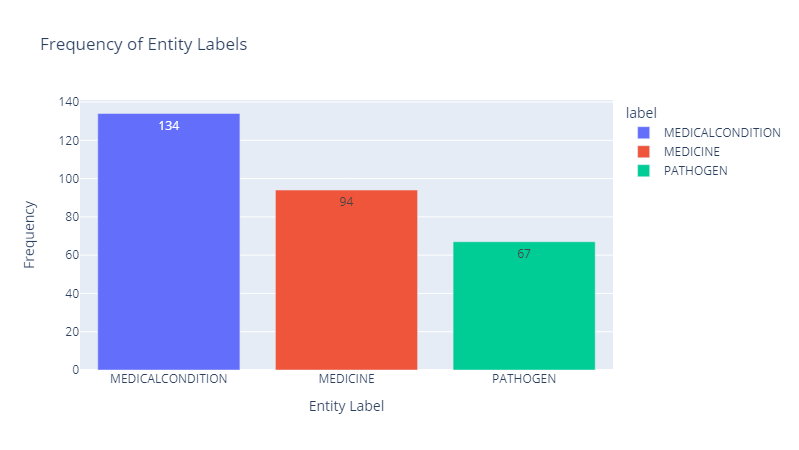
We will use the dataset called corona2 from Kaggle to identify Natural Entity Recognition to identify Medical Condition, Medicine names and Pathogens. This dataset is already annotated.
Labels:
- Medical condition names (example: influenza, headache, malaria)
- Medicine names (example : aspirin, penicillin, ribavirin, methotrexate)
- Pathogens ( example: Corona Virus, Zika Virus, cynobacteria, E. Coli)
Dataset Definition
| Text |
string |
Sentence including the labels |
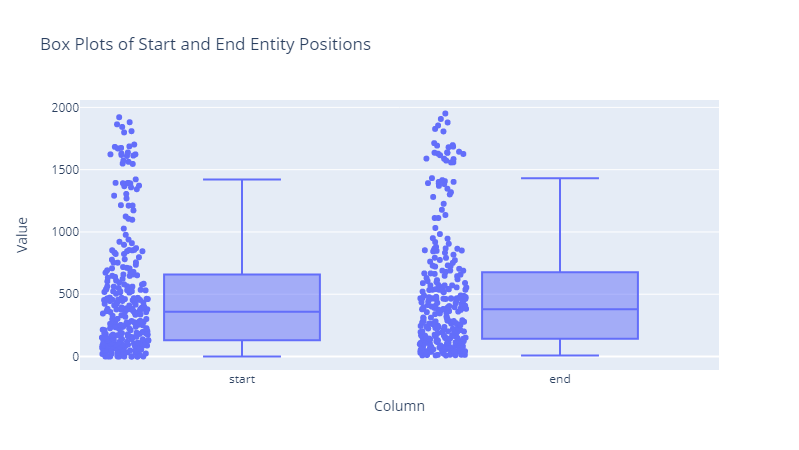
| Starts |
integer |
Position on where the label starts |
| Ends |
integer |
Position on where the label ends |
| Labels |
string |
The label( Medical Condition, Medicine or Pathogen) |
Dataset Sample
Buprenorphine has been shown experimentally (1982–1995) to be effective against severe, refractory depression.
Dataset Visualization - Labels
![]()
Data Visualization - Position
![]()